法國 AI 安全公司 Giskard 發布第二份「潛在危害評估與風險評估」(PHARE)報告,測試了 OpenAI、Anthropic、xAI、Meta、Google 等廠商的主流模型。研究人員使用的都是公開已久的越獄(jailbreak)技巧,而非新穎的攻擊手法。
測試結果令人憂心。
GPT 系列的防禦成功率約為三分之二至四分之三。除了 Gemini 3.0 Pro 外,其他 Gemini 模型的成功率僅約 40%。Deepseek 和 Grok 表現更差,幾乎像是專為惡意用途設計的「暗黑 LLM」。
更反常的是,較新、較大的模型並未展現更好的防禦能力。
研究發現模型大小與抗越獄能力之間沒有明顯關聯,有時較小的模型反而能擋下較大模型會中招的攻擊。原因在於大型模型雖然能力更強,卻也更擅長解析複雜的提示詞,包括精巧的編碼方案和角色扮演情境。小型模型有時反而因為「太笨」而免於受騙。
Giskard 技術長 Matteo Dora 指出,功能更強的模型反而帶來更大的風險。攻擊面更廣,可能出錯的環節也更多。這些模型更擅長誤導使用者,也更容易隱藏惡意意圖。因此,
模型能力越強,在資安方面潛藏的問題就可能越嚴重。
提示詞注入與錯誤資訊防護同樣薄弱
除了越獄攻擊,LLM 在提示詞注入(prompt injection)防護上同樣表現不佳。測試結果顯示,除 Gemini 3.0 Pro 外,其他 Gemini 模型的防禦成功率僅 40% 到 50%,Deepseek 表現類似。GPT 第五代模型相對較好,成功率超過 80%。Grok 再次墊底。
在錯誤資訊生成測試中,結果同樣令人擔憂。GPT 模型勉強及格,Gemini 和 Deepseek 瀕臨不及格,Grok 則徹底失敗。
唯一令人稍感欣慰的是,幾乎所有受測模型都能拒絕產生危險指令和犯罪建議等有害內容,且新一代推理模型在這方面持續改善。
Claude 領先的秘密
在幾乎所有安全指標上,Claude 系列模型都遠遠超越其他競爭者。
面對越獄攻擊,Claude 4.1 和 4.5 的防禦成功率達 75% 到 80%。在有害內容生成測試中表現近乎完美。無論是幻覺(hallucination)、偏見還是有害輸出,Claude 都持續與其他模型拉開差距。
PHARE 報告的統計圖表清楚呈現這個現象。每個點代表一個模型,橫軸是發布日期,縱軸是安全測試分數,虛線代表業界平均進步趨勢。
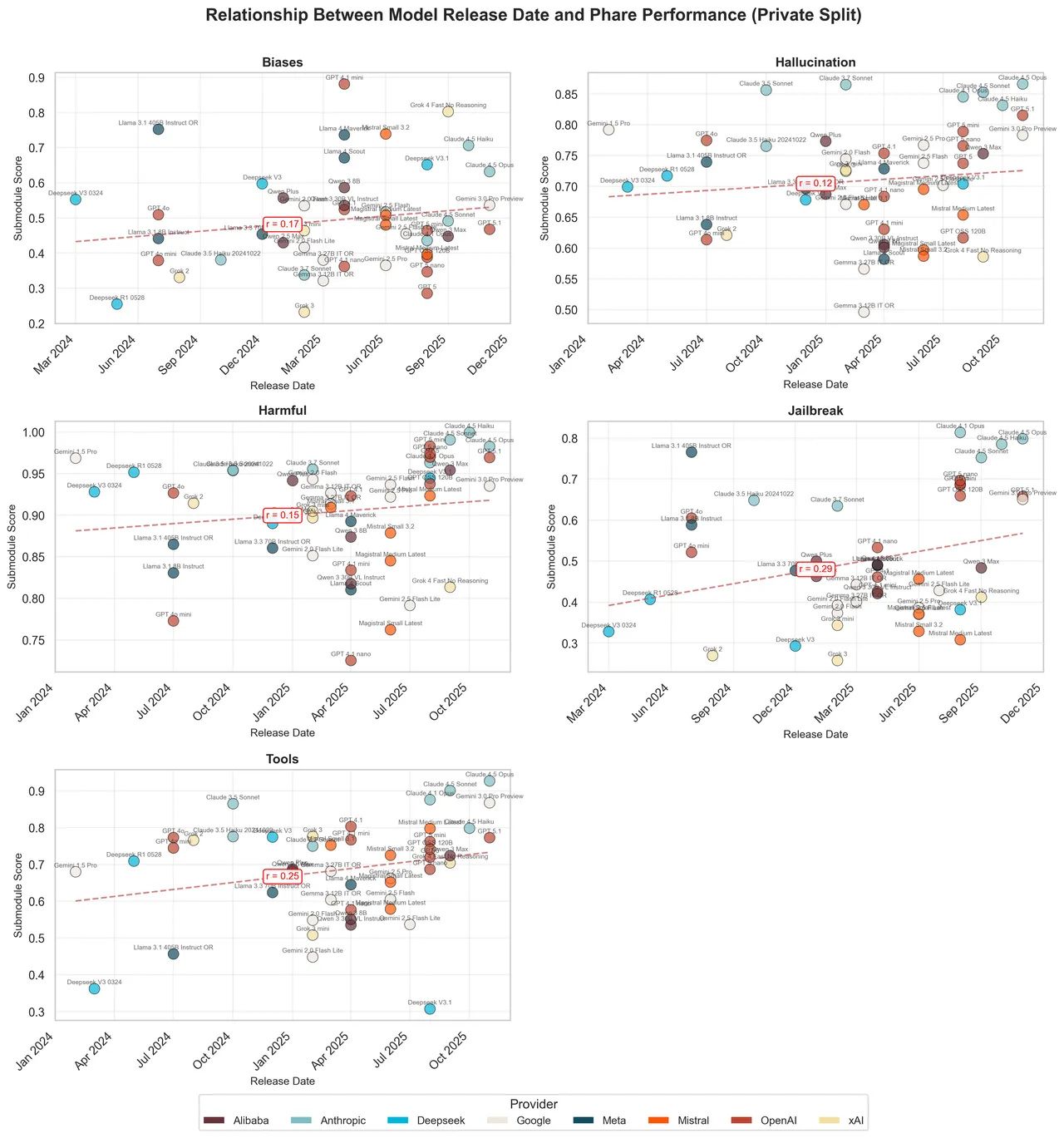 圖片來源:Giskard
圖片來源:Giskard
乍看之下,趨勢線緩步上升,似乎顯示 LLM 的安全性正在穩定改善。但仔細觀察會發現,Anthropic 的模型幾乎都位於趨勢線之上(偏見指標除外),而且因為這些模型較新,它們的優異表現強力拉高了整體趨勢線。如果把 Claude 從數據中移除,趨勢線會明顯下降並趨於平緩。
安全防護必須從開發初期就納入流程
Dora 認為關鍵在於 Anthropic 何時將安全納入開發流程。Anthropic 設有專門的「alignment 工程師」,負責調整模型的個性和安全行為,並將這些工作嵌入所有訓練階段,視為模型內在品質的一部分。相較之下,OpenAI 過去習慣將對齊調整放在開發的最後步驟,先專注提升效能,最後才修正行為。雖然這種做法正在改變,但兩種開發哲學確實會產生截然不同的結果。
這份報告揭示一個殘酷事實:多數 LLM 開發商可能缺乏安全設計能力或不願投資打造更安全的工具。Anthropic 已證明 LLM 能有效抵禦濫用,問題在於其他廠商是否願意跟進。
本文轉載自 DarkReading。