基於大型語言模型(LLM) 的生成式人工智慧技術呈爆炸性增長,機器已經能夠生成接近甚至超過人類平均水準(效率)的文本、圖像甚至程式碼的能力。整合LLM的開源項目數量正快速增長。OpenAI推出ChatGPT僅7個月,目前GitHub上已經有超過3萬個使用GPT-3.5系列LLM的開源專案。
儘管需求空前旺盛,但生成式AI/LLM技術面臨的安全風險也與日俱增,如利用先進的自學習演算法共用敏感業務資訊、惡意行為者利用生成式AI提高攻擊力。
近日OWASP發佈了大型語言模型應用常見的10個嚴重的漏洞,強調了LLM面臨的潛在風險、漏洞利用的難易程度和普遍性。OWASP提出的LLM漏洞範例包括:提示注入、資料洩露、沙箱機制不充分和未經授權的程式碼執行。
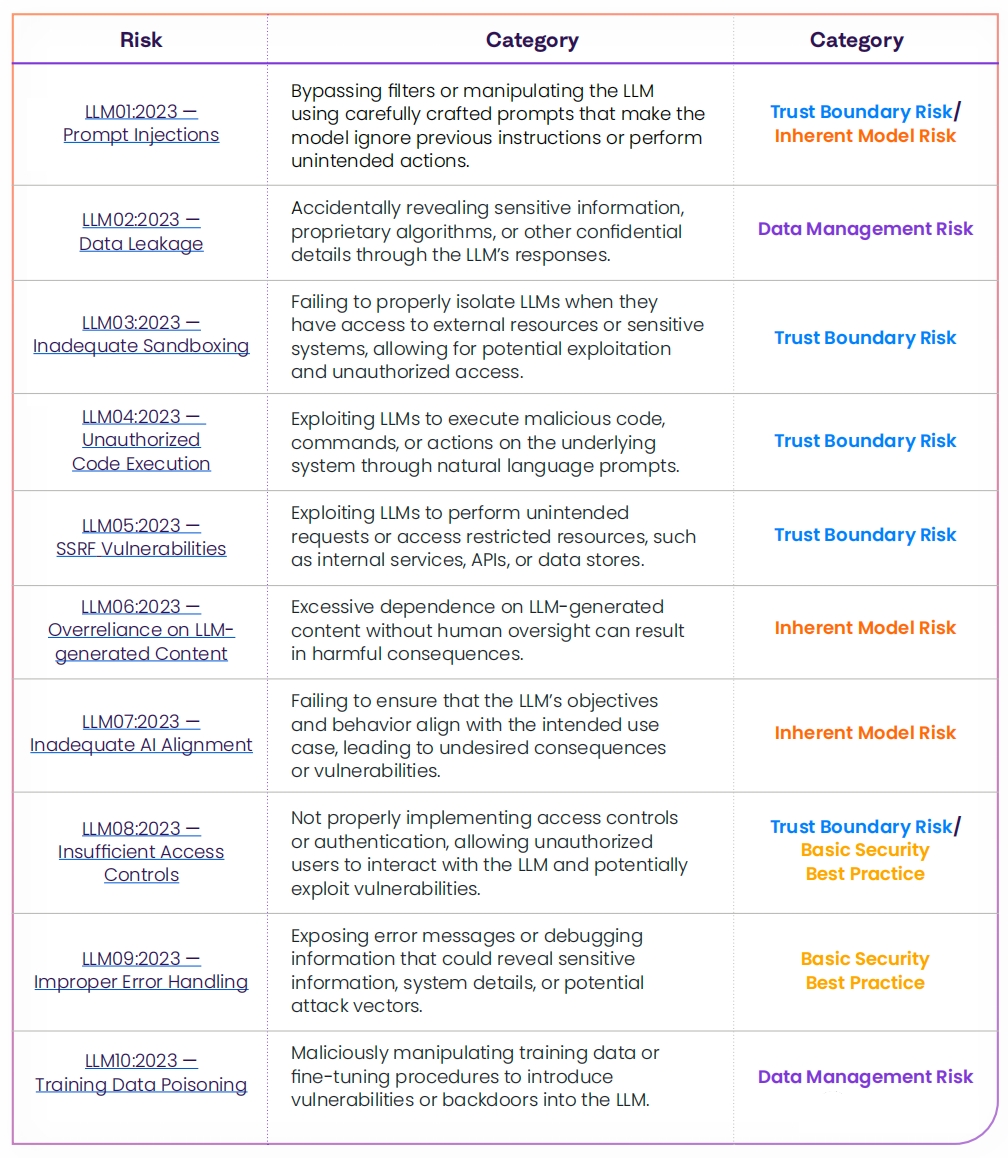 OWASP大型語言模型十大安全性漏洞
OWASP大型語言模型十大安全性漏洞
OpenSSF記分卡評估LLM
軟體供應鏈安全公司Rezilion的研究人員調查了GitHub上50個最受歡迎的生成式AI項目的安全狀況。他們使用開源安全基金會(OpenSSF)記分卡來評估大型語言模型(LLM)開源生態系統。結果發現,生成式人工智慧開源專案越流行、越新,其安全性就越不成熟。
OpenSSF記分卡是OpenSSF組織設計的一個工具,用來評估開源專案的安全性。OpenSSF評估所依據的指標是程式碼資料庫本身的問題,例如漏洞數量、維護頻率以及是否包含二進位檔案。OpenSSF能檢查軟體專案供應鏈的不同部分,包括原始程式碼、建立依賴項目、測試和項目維護,以確保設計者遵守安全最佳實踐和行業標準。
OpenSSF的每項檢查都有一個與之相關的風險級別。然後將各個檢查分數換算成總分數,以評估專案的整體安全狀況。目前,OpenSSF共有18項檢查,可分為三大類:整體安全實踐、原始程式碼風險評估和構建過程風險評估。
OpenSSF記分卡為每項檢查分配0到10之間的風險級別分數。得分接近10的專案表示高度安全且維護良好,而得分接近0則表示安全狀況較弱,維護不足且易受開源風險影響。
Rezilion的研究揭示了一個令人不安的趨勢:生成式AI/LLM項目越受歡迎(基於GitHub的星級受歡迎程度評級系統),其安全評分就越低(基於OpenSSF記分卡)。
研究人員指出,LLM項目的受歡迎程度本身並不能反映其品質,更不用說安全狀況了。GitHub上最受歡迎的GPT項目,Auto-GPT擁有超過13.8萬顆星,上線不到三個月,其記分卡得分僅為3.7。檢查50個項目的平均得分也只有4.6分(滿分10分)。
圍繞LLM的開源生態系統的成熟度和安全狀況還有很多不足之處。事實上,隨著這些系統越來越受歡迎,普及度越高,如果開發和維護的安全標準保持不變,重大漏洞將持續湧現,不可避免地會成為攻擊者的目標。
降低LLM安全風險最重要的方法是「安全左移」
隨著生成式AI和LLM系統的應用不斷增長,給企業帶來的風險預計將在未來12到18個月內發生重大變化。如果圍繞LLM的安全標準和實踐沒有重大改進,針對性的攻擊和發現系統漏洞的可能性將會增加。企業必須保持警惕並優先考慮安全措施,以緩解不斷變化的風險並確保負責任和安全地使用LLM。
降低LLM安全風險最重要的方法是「安全左移」-在開發基於AI的系統時就採用安全設計方法來應對LLM的風險。企業還應該利用安全人工智慧框架(SAIF)、NeMo Guardrails或MITRE ATLAS等現有框架,將安全措施納入其人工智慧系統中。
企業還需要監控和記錄使用者與LLM的互動,並定期審核和審查LLM的回應,以檢測潛在的安全和隱私問題,並對應更新和微調LLM。
本文轉載自Rezilion部落格。