巨量資料技術在近兩年內受到銀行、電信營運商、大型零售商、金融機構等產業的重視,有許多企業已陸續採用資料分析平台、工具或透過專業諮詢服務嘗試尋找合適的資料分析策略。 對企業內部而言,儼然存在對新一代巨量分析平台的適應與對傳統IT維運、思維上的衝擊與挑戰。衝擊的是為處理半、非結構化資料、程式設計架構與模型與搭配演算法的改變等,挑戰在於不同的部門甚至於不同的分公司之間存在各種不同應用工具的整合與協調等工作。
在眾多巨量資料的相關應用技術中,又以Apache基金會開源專案所開發的技術工具Hadoop(註1)等相關系統核心、資料分析工具吸引最多企業用戶與開發者的關注。龐大的開發能量除了集合來自各領域的專才,開源維護社群更會藉由網路論壇(國內、國外)分享Hadoop的建置經驗、流程與架設心得。自2006年1月,Doug Cutting將相關Hadoop程式碼從Nutch專案中獨立出來,六年後,於2011年12月,Apache基金會更釋出了Hadoop專案第一個1.0正式版。Apache基金會也特別在官網上宣示,這是Hadoop專案的里程碑,代表著Hadoop已經為企業應用做好準備。在這正式版裡,Hadoop針對資料存取與運算安全性增加了Kerberos(註2)驗證、HDFS的HTTP存取與Append功能等,使Hadoop更具備了企業應用所需要的重要功能。而以Apache Hadoop為基礎所開發的巨量資料解決方案中,目前就有Hortonworks以及Cloudera兩大商用版本,從資料處理平臺底層到前端的資料分析工具,模組化與快速部署於企業內相關基礎建設等,相關的延伸應用套件與工具也越來越多,逐漸朝完整的生態體系進化。
註1:Hadoop採用分散式處理技術且能透過水平擴充方式來增加資料的處理能力。其專案的共同創始人Doug Cutting 原先是要打造一個開源的搜尋引擎(Nutch),但卻遇到了儲存大量網站資料的難題,剛好Google在2003到2006年間,對外公開了內部搜尋引擎的三大關鍵技術,分別是Google的GFS檔案系統、大規模叢集上的運算技術MapReduce,以及分散式儲存系統Bigtable。自2006年以來,從Nutch專案中獨立出來的Hadoop核心系統與相關應用已廣泛的被應用在巨量資料分析上。
註2:Kerberos身份認證系統原屬於由美國麻省理工學院所發展的一個雅典(Athena)計劃中的一部份,由Miller和Neuman兩位學者負責研發。最初為一套以 Needham-Schroeder認證協定為基礎而建置的第三者身份鑑別性協定並使用於UNIX 作業系統上的身份認證系統,然而近年來支援此認證系統的廠商越來越多,包含有微軟作業系統與相關知名Linux系統供應商。
對企業已部署私有雲或具備一定規模的IT基礎建設而言,如何快速整合現有企業內部身分管理系統、傳統的資料庫和資料倉儲環境和運行Hadoop基礎環境而不會干擾到現有IT環境與線上系統,儼然是企業選用相關巨量資料分析平台、技術等首要考量因素之一。因此在以下幾個章節會就現有Hadoop平台安全性架構與相關設計考量與實作做進一步介紹,與如何整合Kerberos與LDAP(Lightweight Directory Access Protocol)等認證服務集合成多租戶安全性以利快速整合既有企業服務、以及相關延伸閱讀,希望讀者可以對複雜的資料安全與平台有進一步的瞭解。
Hadoop 安全性架構
巨量資料相關的安全性議題重要嗎? Hadoop系統管理與開發者對相關安全性的掌握度為何?當我們嘗試整理過去到現在Apache Hadoop社群裡的所有問題追蹤清單(Apache JIRA),我們驚訝地發現安全性問題僅佔總問題的3 %。但細究各問題分類,我們發現Hadoop架構中主要核心系統HDFS與MapReduce(HDFS是一個分散式檔案儲存系統, MapReduce則是處理巨量資料的程式平行運算架構)安全性相關問題所佔的比例趨勢與非安全性問題呈反向關係(見圖1,與右半邊相比)。如圖1所示,Hadoop Common、HDFS與MapReduce等安全性相關問題佔全部問題的百分比相較同類型問題多出5到10個百分比。而對其他相關分析工具或系統來說其趨勢表現明顯的,就以往Hadoop維運經驗而言,HDFS與MapReduce屬底層核心系統,其他相關分析工具與HBase資料庫等屬上層應用,因此對可能觸及安全性議題而言,底層系統建置、設定與相關整合議題確實可能遇到較多安全性設置錯誤。這也解釋了單單就Hadoop Common、HDFS與MapReduce等種類議題就佔了近73 %。
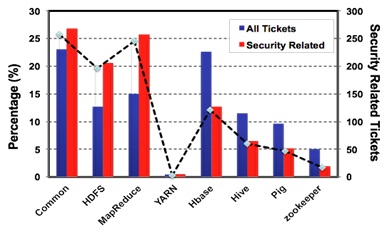
圖1:從2011到2012,Apache基金會Hadoop核心與資料分析應用工具等開源計畫安全性相關問題佔全部問題的百分比。(資料來源:本文作者整理)
其實在Hadoop1.0或CDH3版本之前,Hadoop的設計架構裡並不存在安全認證的實作,且預設叢集中所有的工作節點都是可相互信任的。所以使用者與HDFS或者MapReduce工作運行之間進行資料傳遞與交互指派運算單元時並不需要進行相互驗證,導致在Hadoop叢集中存在惡意使用者偽裝成真正的使用者或者伺服器入侵的可能性,或惡意的派送運算作業、修改JobTracker狀態、竄改HDFS檔案系統上的資料、偽裝成NameNode(註3)或TaskTracker等來接受其他派送的運算工作等。
註3: Hadoop HDFS檔案系統是一個Master/Slave的系統架構。 NameNode執行於Master節點,負責管理文件系統的命名空間(Namespace)以及客戶端對資料Metadata訊息 查詢。另一執行于Master的重要服務是負責安排MapReduce運算層任務的JobTracker。Worker在系統架構裡為一個Slave身份,其上執行了DataNode與TaskTracker服務。DataNode負責儲存和維護資料區塊以及即時彙報給NameNode所儲存的資料區塊與複本以及接受JobTracker指揮,負責執行運算層任務的是TaskTracker程式。
在資安模式的強化上,過去Hadoop最為人詬病的是安全認證強度不足。儘管在0.16版本以後,HDFS檔案系統已增加了授權機制且對目錄和文件的權限控管(Access Control),因此只有授權的伺服器可以存取Hadoop節點上的資料。但是整體上仍缺乏相互認證的機制,以至於無法驗證叢集中的伺服器是否已真正獲得授權。惡意的使用者還是可以輕易的偽裝成其他用戶來竄改權限,致使權限設置形同虛設,不能夠對Hadoop叢集達到應有的安全保障。譬如Hadoop叢集中伺服器A授權給伺服器B使其具有存取權限,而伺服器C沒有獲得這樣的授權,但因為舊版Hadoop不會驗證伺服器的身分,所以伺服器C可以更名為伺服器B來取得伺服器A的存取權限。
早期的Hadoop開源設計方向只考慮作為內部專用系統使用(註4),但考慮在企業應用上時,往往會將Hadoop作為企業IT架構中的一個重要分析平臺,或同時間開放給多套應用系統來存取,因此導入認證機制來確認存取者(使用者或伺服器)的身分以及限制系統中執行的應用程式僅能存取到賦予限制條件的資料,以保護企業內部的機密資料就更顯重要。
由於開發者來自於社群,且專案本身牽涉範圍較為複雜,Hadoop專案的版本更新速度向來很慢,往往要等上好一段時間才會有更新版本釋出。在Hadoop 1.0版問世前,社群主要維護0.20系列和0.23系列2個版本。0.20版是Hadoop先前的穩定版本,1.0版的前身正是0.20版系列。而0.23系列則屬於開發版本,尚未穩定的新功能會先加入在此版本中讓有興趣的Hadoop社群開發者來測試。1.0版新增的關鍵功能包括了HBase資料庫套件內建了Append的支援(註5)、HDFS檔案系統支援Web HTTP的存取、企業最關心的資安模式的強化,以及多項效能的改善。在Kerberos認證功能增加後,我們就可以實作與企業內部目錄伺服器的整合,以方便檢查存取者的身分。
註4:除了缺乏認證機制的系統安全性外,Hadoop系統中的NameNode角色仍缺少高可用性(HA)的備援設計。
註5:HDFS檔案系統的原本設計為資料寫入後即不能修改,但是可以無限制地取用。可是這樣的設計與Hadoop資料庫系統HBase的功能衝突。HBase需要修改原本寫入的資料檔來插入資料,因此1.0版中將HDFS直接內建檔案附加寫入(Append)的機制,解決了 HBase的資料寫入需求。
我們歸納在Hadoop叢集系統中,如果缺少第三方認證機制,在1.0版本以前惡意使用者就可以:
● 偽裝成其他使用者入侵到一個HDFS 或者MapReduce叢集上,因為JobTracker上沒有使用者認證機制。
● 客戶端如果知道HDFS檔案系統的Block ID即可任意的查看DataNode上Block的資料,因為DataNode上沒有認證機制且DataNode對讀入與輸出亦沒有做認證。
● 任意的結束或更改使用者已執行的應用程式或更改JobTracker的工作狀態,因為JobTracker上沒有認證機制。
● 使用者可以偽裝成DataNode ,TaskTracker,去接受JobTracker或 NameNode的任務指派,因為缺乏伺服器到伺服器的相互認證。
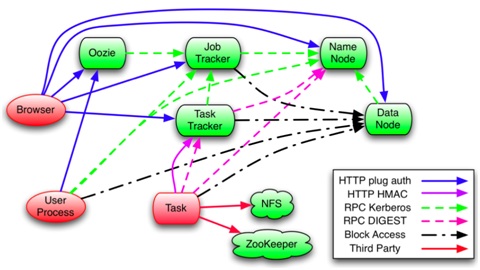
圖2:Hadoop系統中主要認證傳遞路徑與協定。(資料來源:“Hadoop Security Design”, Owen O''Malley et. al., Oct 2009)
Hadoop系統中各核心元件間授權機制與認證路徑如同上圖2所示。對RPC安全機制來說,當用戶使用RPC時,用戶的系統登入名稱會通過RPC協定來傳遞,之後RPC會使用SASL (Simple Authentication and Security Layer)來確定其權限協議(支援Kerberos和DIGEST-MD5兩種)以完成RPC授權。
而HDFS安全機制中,當用戶端使用Kerberos認證機制獲取NameNode初始認證後,會取得一個Delegation Token,這個Token可以作為接下來存取HDFS檔案系統或是派送MapReduce工作的憑證。同樣的,為了讀取HDFS檔案系統上某個文件,用戶端首先要與NameNode認證以獲取相對應Block的存取Token,然後到對應的資料節點上來讀取各資料區塊。除用戶端以外,資料節點在服務初始化的過程中 (向NameNode註冊),也已經取得了認證的Token,當用戶端要從TaskTracker上讀取相關資料區塊時會先驗證其Token,通過後才會被允許讀取。對MapReduce工作運行狀態的追蹤也是採用帶有Kerberos認證的RPC實做的。當授權過的用戶端派送工作時,同樣的,JobTracker會為它產生一個Delegation Token,而該Token會被當作工作的一部分儲存到HDFS檔案系統上,並通過RPC再分發給各個TaskTracker,一旦工作運行結束後,該Token就會失效。
透過Kerberos安全認證,Hadoop已經實做了對伺服器間的安全認證機制,也就是前面提到的用戶端、服務與伺服器之間的認證問題。而對伺服器系統管理員本身,只需手動增加認證的個體到Kerberos資料庫中並在憑證發放中心(KDC, Key Distribution Center)上分別產生伺服器主機與各個節點的Keytab(包含了Host和對應叢集節點的各主機名稱、還有他們之間的加密金鑰),並將這些Keytab分發到對應的節點上。利用這些產生的Keytab文件,Hadoop叢集中的服務節點可以從KDC上獲得與相對應節點通訊的金鑰,進而被另一主機節點所認證,相互之間使用密鑰進行通訊,確保不會有假冒伺服器的情況發生。除此之外,原Hadoop已允許管理者對資料存取、工作派送上的權限控制也相容於以Kerberos所建構的安全認證。以下將繼續深入介紹Kerberos工作原理與運作程序。
本文作者為精誠資訊Hadoop 系統架構師/資深技術處長