2013年4月台灣高鐵發生了2次緊急事件,在4月12日北上的616班次列車發現「行李箱炸彈」事件及4月25日每日清晨例行維修導致行車控制系統訊號異常,因安全考量全線停駛4小時以上事件,這兩個重大緊急事件均是台灣高鐵自2007年1月啟用後6年來首度發生,前者有驚無險,因炸彈客非專業恐佈分子及由旅客及時發現通報高鐵及高鐵警察處理,僅影響該少數旅客,但後者因安全考量全線停駛,卻影響44個班次,估計影響人數,據媒體推算達3萬5千多人,4月29日高鐵董事長歐晉德先生出面道歉,並允諾從寬處理賠償事宜。
關鍵基礎設施保護與企業存活省思
回頭再看高鐵對台灣的重要性,對營運至今,從初期狀況連連,大小問題不斷,至今已經幾乎達每15分鐘一班,由台北出發至高雄2小時,由台北至台中1小時,新竹及桃園分別只要半小時及一刻鐘時間,高鐵改變了台灣的交通生態及國人南來北往的交通習慣,直接衝擊到航空、台鐵及國道客運的業績,現在高鐵便捷及可靠度成為商務及旅遊的主流交通工具,造就台灣的一日生活圈。偶爾在高鐵上我們也會看見有科技業維修工程師,帶著狀似電腦伺服器的大型行李上高鐵,甚至筆者在數年前參與一次政府機關的營運持續演練,模擬資訊系統中斷,需由位於新竹市供應商前來維修,估算1小時抵達,也是搭高鐵在加上前後的接駁轉乘順利抵達,高鐵每日輸運12萬人次,無疑成為台灣本島交通關鍵的基礎建設(Critical Infrastructure, CI)。依我國對CI 的定義,經行政院國土安全辦公室初步研析,國內之關鍵基礎設施可分為八個部門,即:能源、水資源、資通訊、交通、銀行與金融、緊急救援與醫院、中央政府、高科技園區。立法院研議中之「關鍵基礎設施防護條例草案」,將國內的關鍵基礎設施之安全防護範圍區分為八大類別。分別為(1)、重要能源、電力及水利設施。(2)、重要財務、金融設施。(3)、重要衛生、醫療設施。(4)、重要資通訊科技及設施。(5)、重要交通運輸設施。(6)、重要國防軍事設施。(7)、特定專業領域之投資事項。(8)、特定專業領域之產學合作事項。台灣高鐵應屬第(5)類需安全防護關鍵基礎設施無庸置疑。
台灣高鐵4月25日因轉轍器維修造成號誌異常而停駛事件,於筆者截稿前尚在內部調查階段,尚未正式發佈事件調查報告,從台灣高鐵官網當日公佈已成立緊急應變中心進行應變,另故障排除部份訊息僅經由媒體得知係以重新啟動系統方式恢復正常運作。4月12日事件依據4月18日交通部向立法院司法及法制委員會提報之「102年4月12日高鐵列車發現危險物品事件處置過程與檢討情形」專案報告得知,交通部及台灣高鐵訂有「台灣高速鐵路交通事故整體防救災應變計畫」,全線8個車站每年均需針對爆裂物與毒化物侵害進行1次演練,另曾結合警、消、醫療、環保等外援單位實施爆裂物與毒化物侵害辦理過4次演練,合計在2007年至2012年間演練過100次緊急事件處理,使得在4月12日於9:22時高鐵組員經由旅客反映發現置於列車廁所不明危險物體,即能依緊急應變標準程序於9:45停靠桃園站後,立即疏散旅客封鎖月台及該列車,由後續警方支援防爆小組進行進一步排除。此次事件處理顯見交通部與台灣高鐵已具備成熟的緊急事件處理及持續營運管理機制,並透過多次演練及教育訓練落實,但針對事件發生後台灣高鐵管理階層危機處理、一線人員內外部溝通機制及系統災難後原(Disaster Recovery, DR) 仍有相當改善空間。
我們再把視野放大至國際,今年3月20日15:00南韓數家大型金融發生大規模服務中斷事件(Dark Seoul,闇黑首爾事件),數以萬計的ATM及行員使用的個人電腦,疑似遭受國家等級駭客組織,以APT方式侵入,設定同時移除開機程式,導致系統癱瘓,但這些金融機構卻能在1小時內陸續恢復正常營運,相較於前後一個月,台灣2月25日發生數位通UPS火警,影響達24小時及4月25日台灣高鐵停駛4小時來看,卻是亮眼許多,由此看來政府及企業組織緊急事件發生或許不可完全避免,更重要的是如何適切緊急應變、持續營運及從災難中復原是反映組織應變管理及存活能力。
緊急事件處理與營運持續管理框架
緊急事件的種類繁多,大體區分天災、人為破壞及資通安全事件等大類,傳統在處理權責上,天災及人為破壞被歸類於實體安全範圍,在組織內通常歸工程或總務部門負責,資通安全事件通常是由資通訊部門負責,但由於工業控制系統(supervisory control and data acquisition, SCADA)發展愈來愈依賴ICT技術,各種雲端運用促成更多資料中心建置,其運作依賴更多電力或泠卻等實體施設,參考圖1示意,在組織治理角度面,兩者的關係為相互依賴且密不可分。
圖1 關鍵資訊基礎建設保護(CIIP)之關係示意圖
.jpg)
資料來源:資策會MIC委外研究報告及行政院科技會報關鍵資訊基礎設施保護指引
像2010年起,伊朗核能設施SCADA系統遭惡意不法組織以Stuxnet病毒攻擊,感染約3萬台以上電腦,導致伊朗納坦茲核設施的五分之一離心機被迫關閉,重創伊朗核子計畫。2010年的中信銀資訊機房UPS電池失效及今年2月的數位通機房UPS火災都導致了重要業務及網路服務停擺,顯見組織需要一套整合或聯合實體與虛擬的營運持續管理系統(Business Continuous Management System, BCMS)管理架構 ,參考組織架構如圖2。
圖2 營運持續管理(緊急事件處理)編組
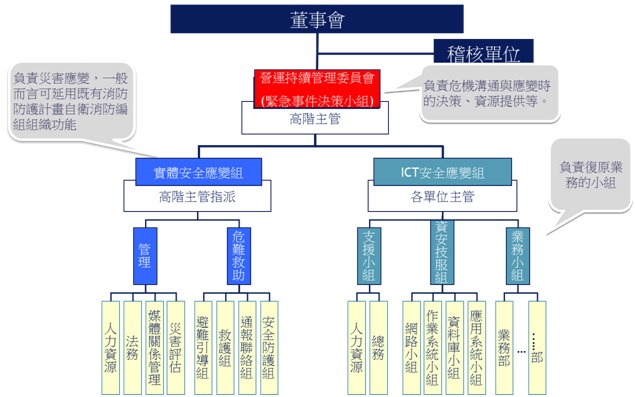
資料來源:勤業眾信管理顧問公司
此參考組織架構以高階主管組成的營運持續管理委員會,負責審查來自實體安全及資通訊安全權責單位針對已識別危安因素(潛在威脅與脆弱點)對關鍵服務或基礎系統產生風險,發展出一系列管理及技術面強化措施,包括針對可能發生單點錯誤的系統元件規劃冗餘(Redundancy)或備援(Backup)機制,日常的實體及資通訊系統監控機制及事件發生後應變及復原計畫,參考的緊急事件及營運持續管理框架如圖3。
圖3 緊急事件處理與營運持續管理參考框架
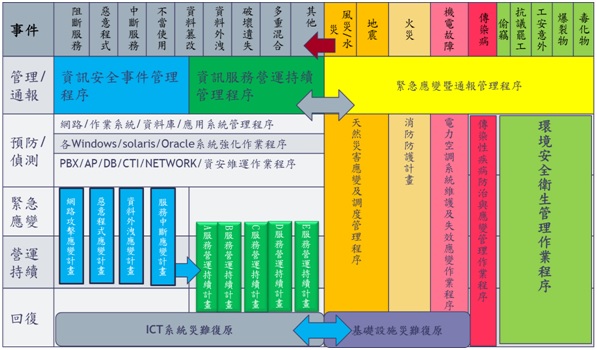
如果把緊急事件發生點當作界限,可區分為平時(危機潛伏期)及緊急應變(危機處理)、營運持續及災難後原等階段,各階段的權責區分、流程與重點,參考如圖4。
圖4.緊急事件處理與營運持續流程、重點及權責示意圖
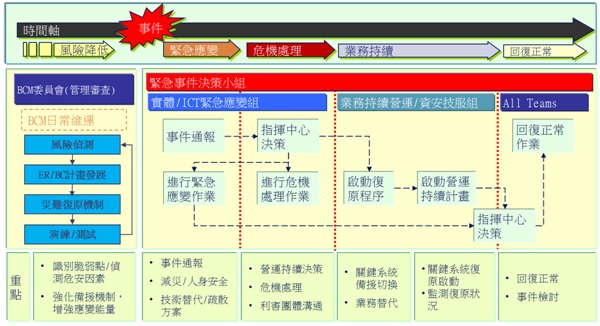
資料來源:勤業眾信管理顧問公司
政府與企業應以審慎心態「事前預防、事中處理及事後復原」的原則來因應,萬不可在事前以僥倖心態,希望事件不會發生在自己的組織,不去做任何風險偵測及強化系統可靠度的計畫,最常見的忽略是因資訊系統快速發展,而跟不上的電力系統老舊或UPS電池逾期不更換,很多企業都為節省成本而刪除預算,一旦發生事件後,卻又能立即更換(很可能先請供應商應急再補採購程序)。
當事件發生時沒有事前計畫應變措施,組織往往是上上下下亂成一鍋粥,處理事件的人不僅要忙於排除故障,還要應付層層的長官、同仁及客戶的詢問,事件狀況上層無法掌握,指揮沒體系,決策沒資訊,一線人員不知如何應變及安撫客戶的怒火,導致災害不斷擴大,危機節節昇高;當事件過後,以得過且過心態,不認真去追究事件發生原因與責任,誠如台積電創辦人張忠謀先生所言:「三流企業解決過去的問題,二流企業解決現在問題,一流企業解決未來的問題」。在美國911事件中,為何像德意志銀行傷亡僅為個位數,隔日即在預設的備援辦公室即恢復運作,有的企業卻隨雙子星大樓一同飛灰煙滅,關鍵差別在於存活下來組織已將緊急事件與營運持續的精神深植於組織文化與員工心中,並預先規劃適當的異地備援及系統復原作業程序,當事件發生後員工能立即進行避難保存性命,接著投入救災及復原企業運作,成為企業持續營運典範。
給政府與企業實務建議
多數緊急事件絕對不是突然發生,也不可能完全避免,政府與部份企業雖已進行全組織風險管理制度導入及在基礎設施規劃災害復原機制,但是否有系統性方法,是否能有效持續落實及維護系統的高可用性,並於事件發生後能從容應變,保障人身安全及計畫目標時間恢復業務活動,以下為實務建議:
1.事前預防階段
1.1 建立緊急事件處理與營運持續管理制度,將營運持續管理政策及目標明確訂出,可參考國際BCMS實務標準像ISO 22301(原BS 25999)及企業實務需求建立。
1.2建立緊急事件處理與營運持續管理組織,將各功能部門適度分工並賦與平時及緊急事件發生責任及轉換時機。
1.3以情境方式由組織管理階層與內外專家共同識別出關鍵基礎系統與重要資通訊服務的脆弱點及可能威脅,進行營運衝擊及風險分析,規劃因應對策及前2項因子研訂需求資源、完成順序。
1.4識別當事件發生時關鍵利害人及相關外部支援單位,建立溝通及連絡機制,必要時納入計畫協同作業及演練範圍。
1.5逐步發展各項平時作業程序及緊急事件發生時應變計畫,定時演練與測試,計畫可行性與目標系統是否能於預定的目標時間(RTO)及服務水準(RPO)回復運作,檢討修正計畫及調整系統作業維護水準。
1.6各項基礎設施重要元件,如電力、消防、空調及環境監控系統需落實定期保養,消耗性元件如電池及重要電子元件,應依原廠建議平均壽限期更換,避免因老化發生故障或釀成災害。
2.事中處理階段
2.1當事件發生時,應立即通報至預設事件處理窗口,進行事件分類分級,成立適當層級應變管理中心,由高階主管擔任指揮官,由事件相關專業、業務、法務、公關及資通訊部門組成幕僚小組,蒐集事件狀況、研討行動方案,輔助指揮官決策與指揮行動,必要時可邀請緊急事件處理、法律及外部專案到場提供意見。
2.2一線現場處理單位主管,應於現場能掌握狀況安全且通訊良好適當位置,將指揮現場人員依計畫轉換任務,善用可用通訊手段如無線電、行動電話、簡訊或廣播等系統指揮調度,儘可能將事件處理人員與通報人員分工,人力不足可考慮召回休假人員協助或請上級單位派員協助。
2.3考量群眾持續聚集及煽動騷暴事件發生,應告知處理進度並初步宣告替代方案或賠償原則,儘快疏散人群,針對訴求強烈個案,可邀請與群眾隔離場所進行溝通,必要時請求警政單位協助維持秩序。
2.4應變中心應以人身安全保障為第一優先考量,確認安全無虞後,始得依蒐集狀況及參考幕僚及專家意見,決定是否啟動備援與營運持續計畫。
2.5事件處理過程中應依主管機關規定進行重大事故通報,並保留相關狀況及決策及處理記錄,以符合法律及主管機關規範。
2.6基礎設施或資通訊服務系統於災害發生後,在安全無虞狀況下,進行故障排除應依原計畫目標回復時間(RTO)及切換至備援系統啟動需要時間的差值,決定營運持續啟動時限內,例如服務的RTO為1小時,切換至備援需要20分鐘,決策小組需要於事件發生後40分內(60-20=40min)決定是否啟動營運持續計畫及啟動備援。
3.事後復原階段
3.1當緊急事件危安因子消失後,應著手進行系統復原,切回已回復主系統運作恢復正常服務水準,不可以備援系統持續運作下去,而不去復原主系統,萬一系統再次發生緊急事件,將無備援可用。
3.2當系統復原後,應當持續監控一段時間,通常至少24小時,避免危安因子再次死灰復燃。
3.3因緊急事件動員的應變及復原組織,應隨緊急事件狀況轉換任務,最終應回復至原有的營運任務。
3.4由管理階層指派具獨立性成員組成事件調查小組,調查事件發生根因,以利研擬後續改善作為,並修正原有的相關管理及作業程序。應針對事件中責任進行追處,並獎勵在事件中盡責或表現優秀人員,以建立「有功必賞,打破要賠」的組織價值觀。
結語
俗語說「天有不測風雲,人有旦夕禍福」,一語道破古往今來混沌的世界,隨時隨地都有可能發生災害或緊急事件,但災害的發生其非完全不可測及事先預防,發生之後有的組織或人存活下來,絕非單憑老天庇佑與運氣,另一句諺語說得好「天助自助者也」,因應組織未來的風險,睿智的經營管理者應該已深諳如何因應之道。
作者現職為企業風險服務管理顧問